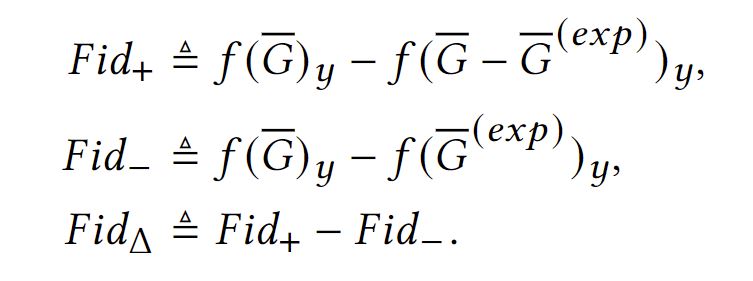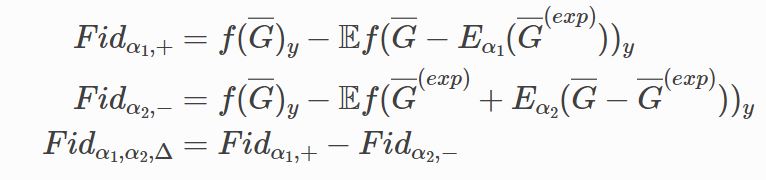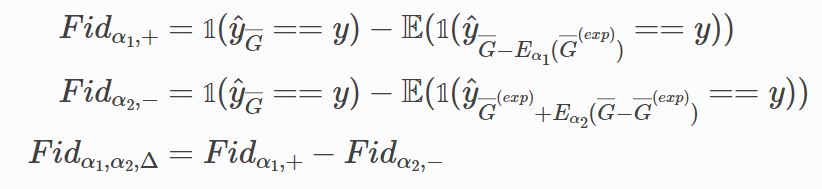Robust Fidelity ( R-Fidelity ) [paper] [code]
Abstract
This paper studies this foundational challenge, spotlighting the inherent limitations of prevailing fidelity metrics, including $Fid_+$, $Fid_−$, and $Fid_\Delta$. Specifically, a formal, information-theoretic definition of explainability is introduced and it is shown that existing metrics often fail to align with this definition across various statistical scenarios. The reason is due to potential distribution shifts when subgraphs are removed in computing these fidelity measures.
Subsequently, a robust class of fidelity measures are introduced, and it is shown analytically that they are resilient to distribution shift issues and are applicable in a wide range of scenarios. Extensive empirical analysis on both synthetic and real datasets are provided to illustrate that the proposed metrics are more coherent with gold standard metrics.
Explaining Deep Learning Models
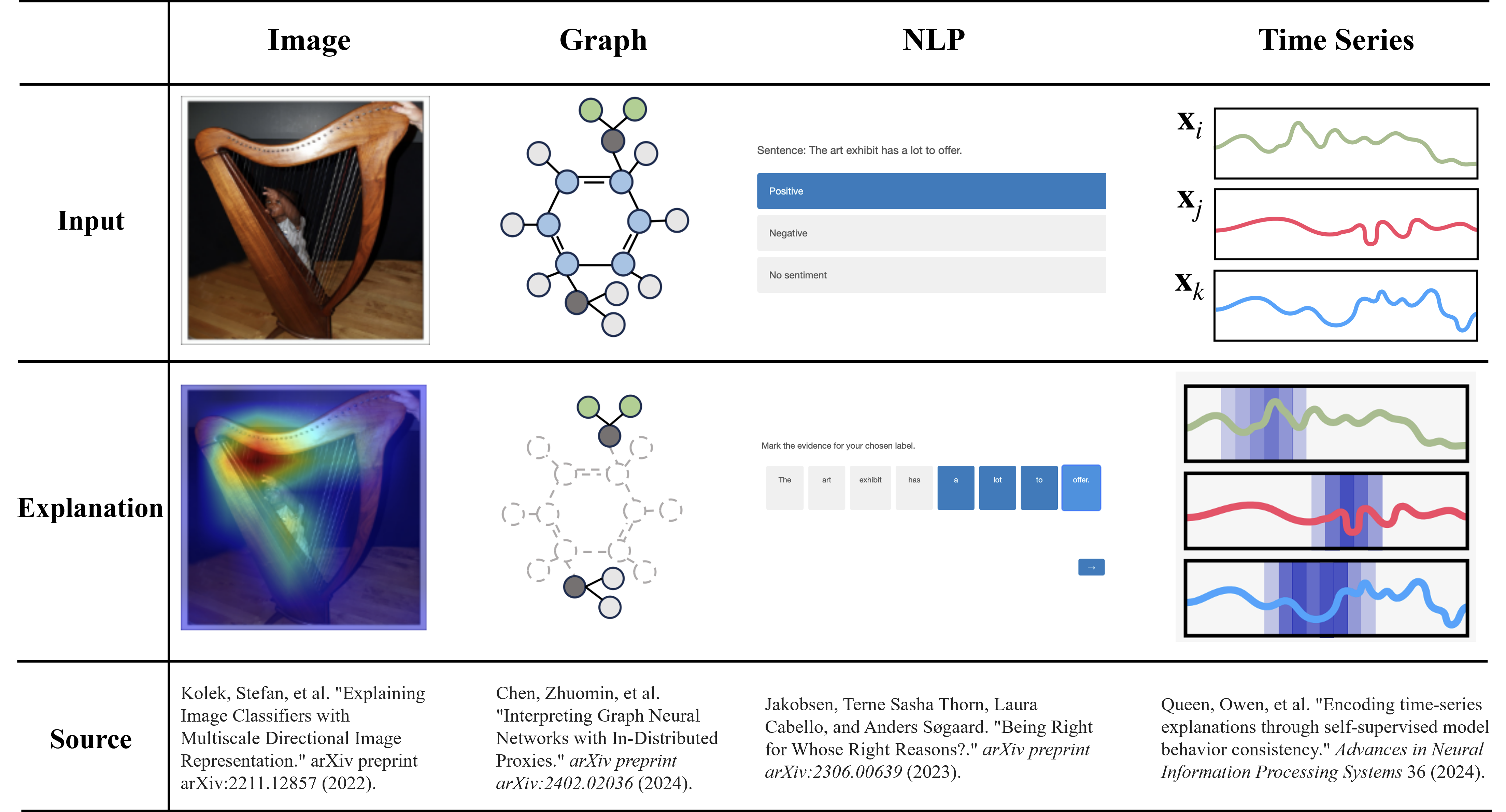
Explainable AI helps us to understand how the model makes predictions. The following figure shows some explained methods. In the graph domain, an explanation is usually a subgraph, such as NH$_2$ and NO$_2$ in the Mutag dataset. In NLP tasks, the explanations are the most important words. For time series, the explanations are the time stamps. In an image, the explanation is the foreground that the model focuses on. In the current paper, we first introduce our method on the graph domain.
Fidelity and OOD Problems.
To evaluate the faithfulness of the explanation methods, the Fidelity method are introduced. The tuitive idea is if the explanation part is critical for the prediction model, the model can infer the results from explanation. On the contrary, the non-explanation part will cause the shifts of pridiction. Based on this idea, we can have $Fid+, Fid-, Fid_\Delta$. Formally, we have:
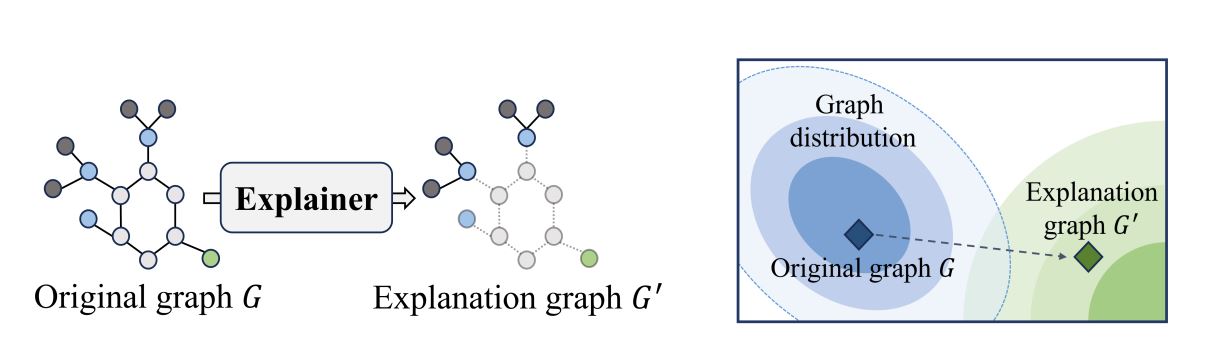
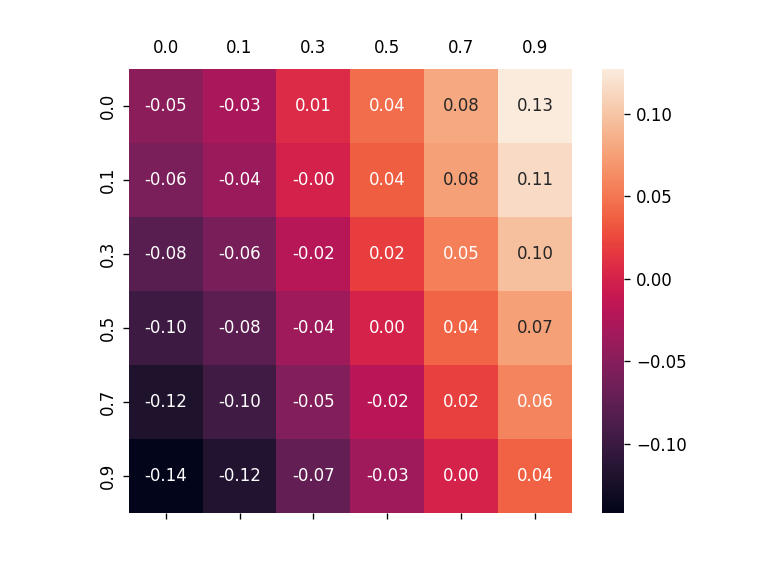
According to Fidelity definition, there exists Out-of-Distribution(OOD) problem might cause inaccurate results because of the domain shift between original training data and explanation data. In some concurrent work, they also mentionedt this problem, such as OAR,GInx-eval. We select one figure from (Zhuomin Chen et. al.) to illustrate this phenomena.
Robust Fidelity
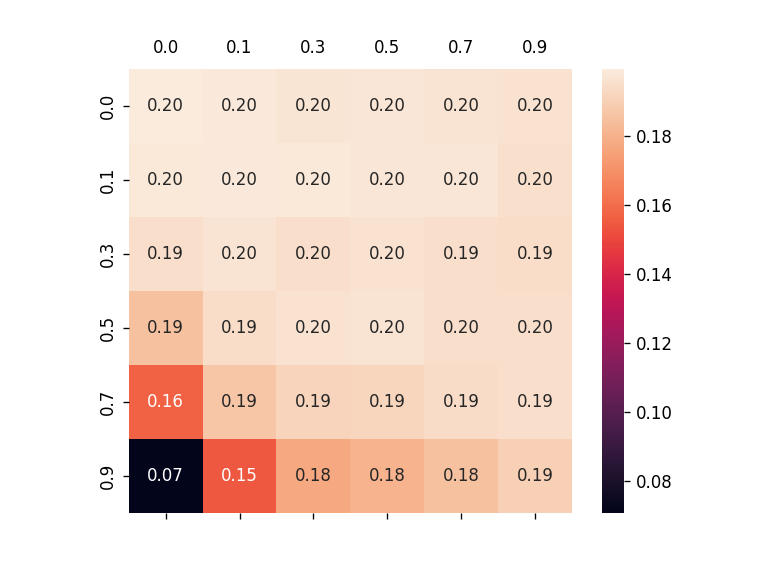
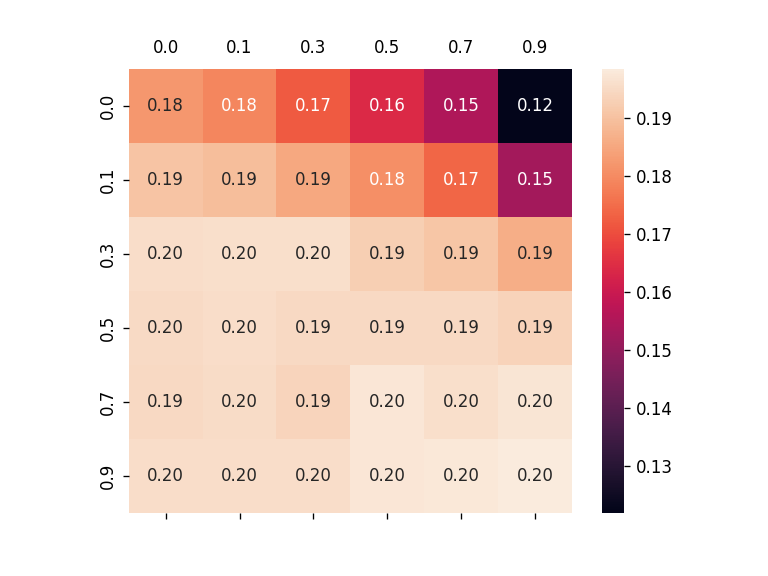
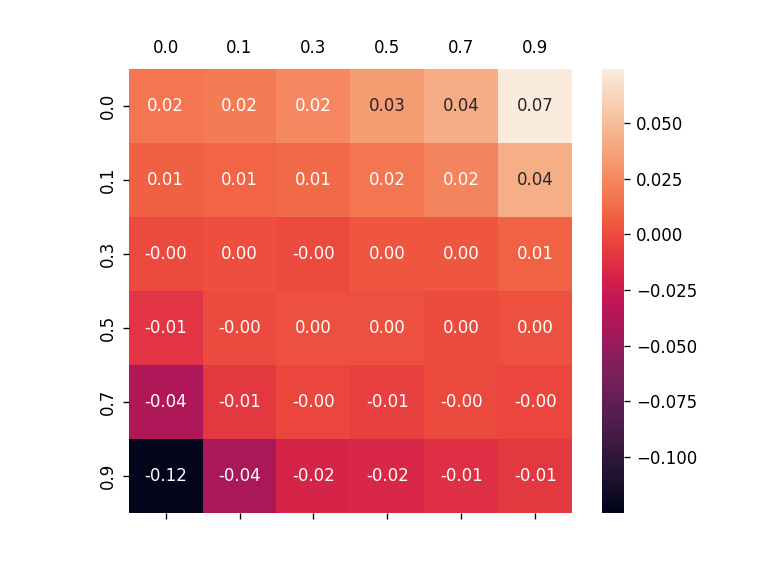
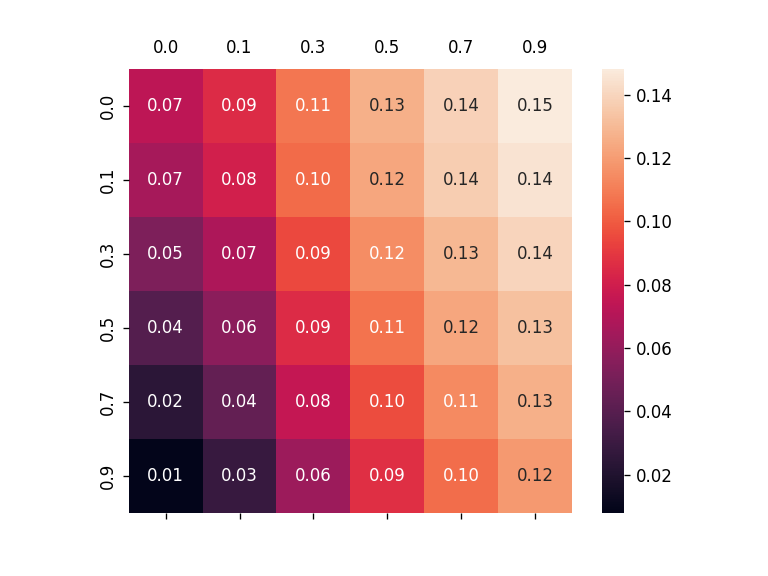
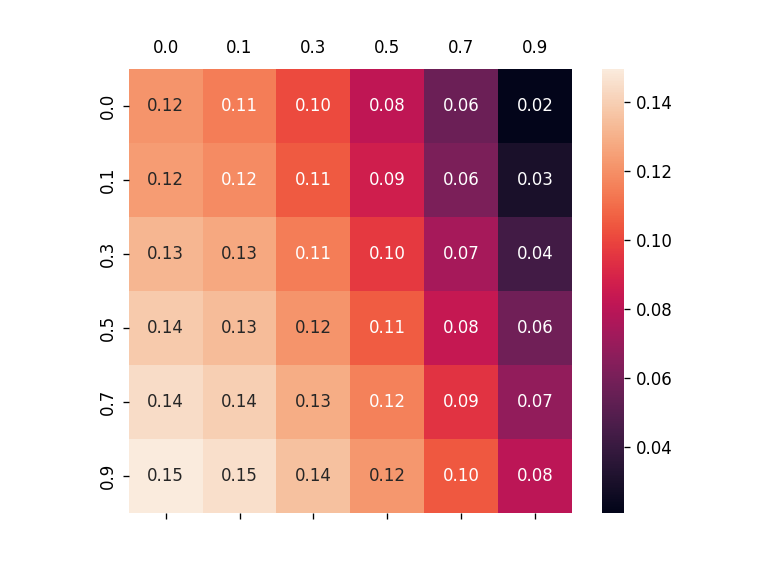
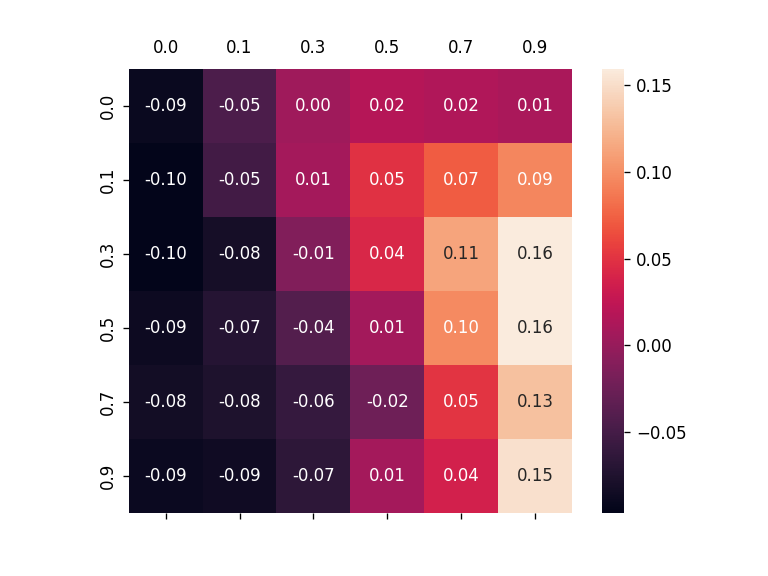
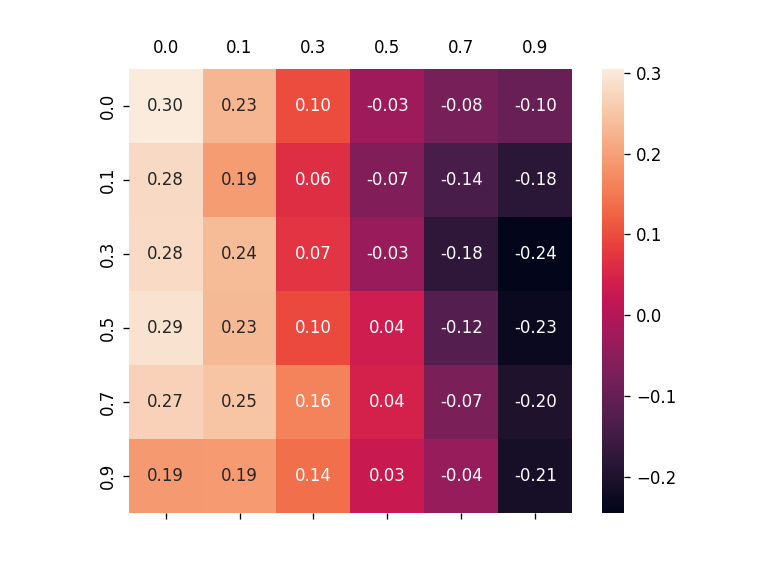
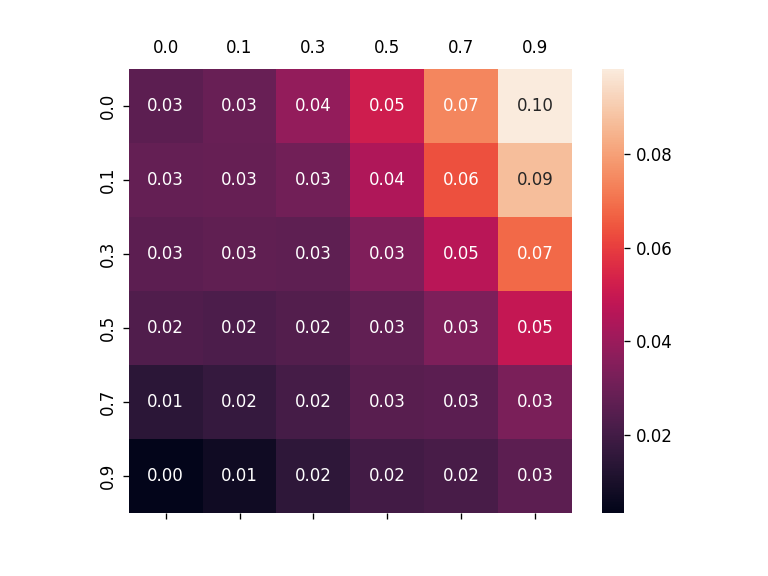
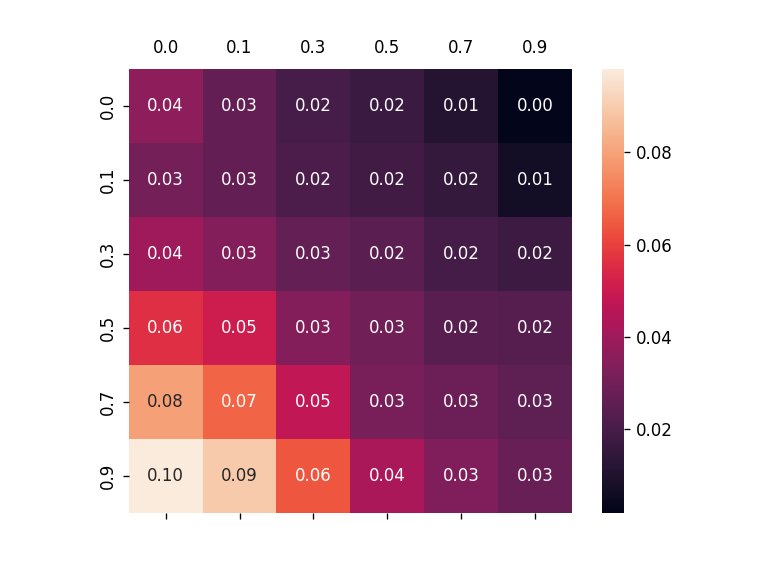
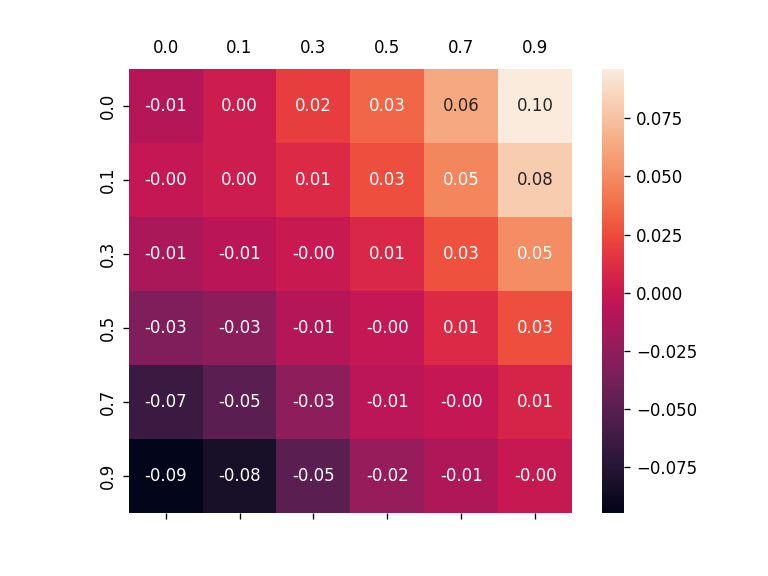
To alleviate this problem, this work introduces a new metric, robust fidelity, as a new faithfulness metric. In this method, we randomly delete edges from the explanation/non-explanation subgraph by using a hyperparameter $\alpha$. Random sampling technology is used to achieve that. Formally, we have the probability-based robust fidelity scores :
Similarly, we can have the accuracy-based robust fidelity scores :
The algorithm of this method can be summarized as follows:
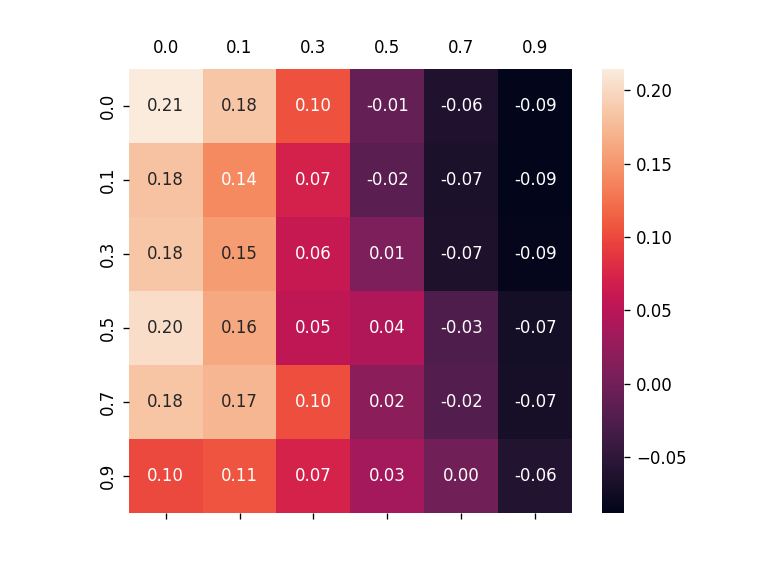
We also use a figure to illustrate how our method works.
Extend to Image, NLP, and Time Series
We provide the furture word in Finetune Fidelity(F-Fidelity).
Graph Experiments
If this work is helpful for you, please consider citing our paper.
@inproceedings{zheng2024towards,
title={Towards Robust Fidelity for Evaluating Explainability of Graph Neural Networks},
author={Xu Zheng and Farhad Shirani and Tianchun Wang and Wei Cheng and Zhuomin Chen and Haifeng Chen and Hua Wei and Dongsheng Luo},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=up6hr4hIQH}
}